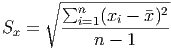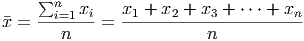
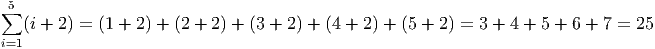
The sigma notation (the symbol is the uppoercase Greek letter S, for ”sum”) provides a much cleaner way to write the formula. After, all, if we had to add from i = 1 to i = 10, 000, writing each term out by hand would be tedious and rather pointless.
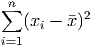
The total variation is always positive (since you are adding a bunch of squares of numbers) or zero (if each observation is equal to the mean).