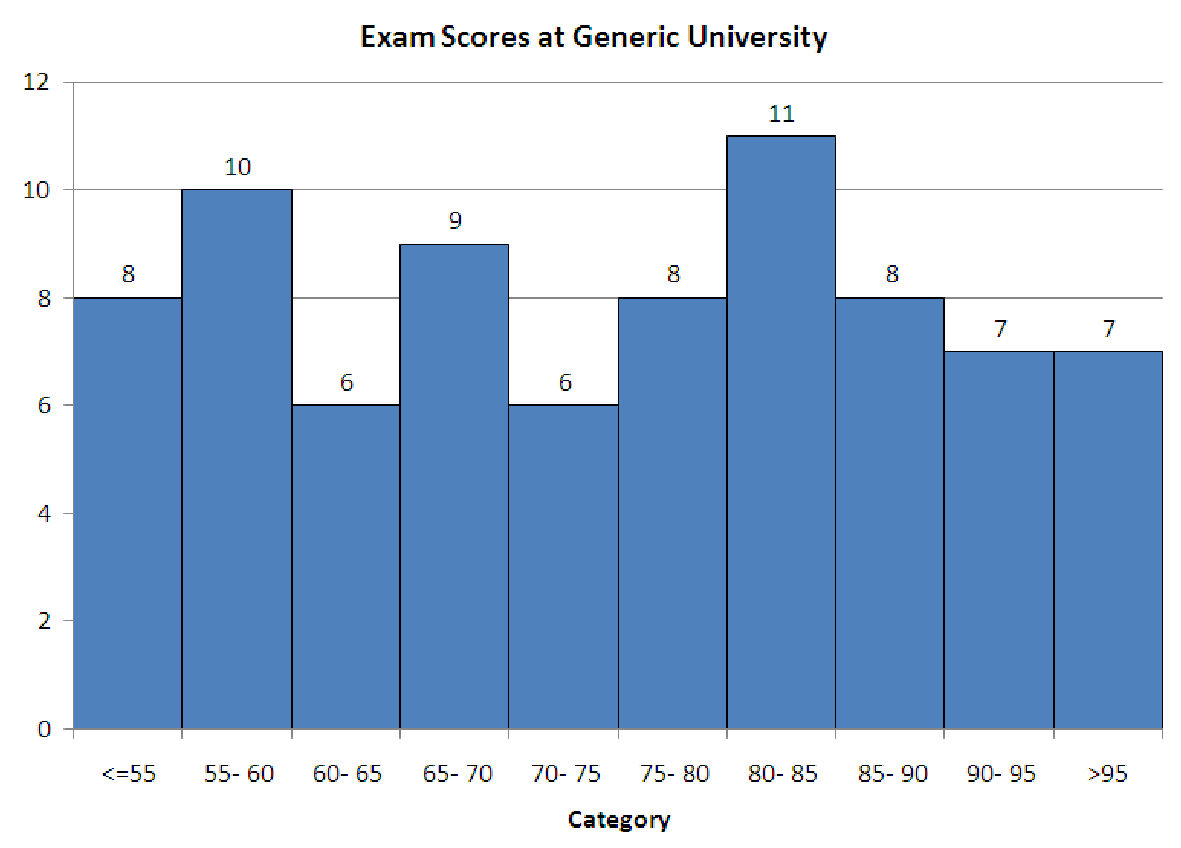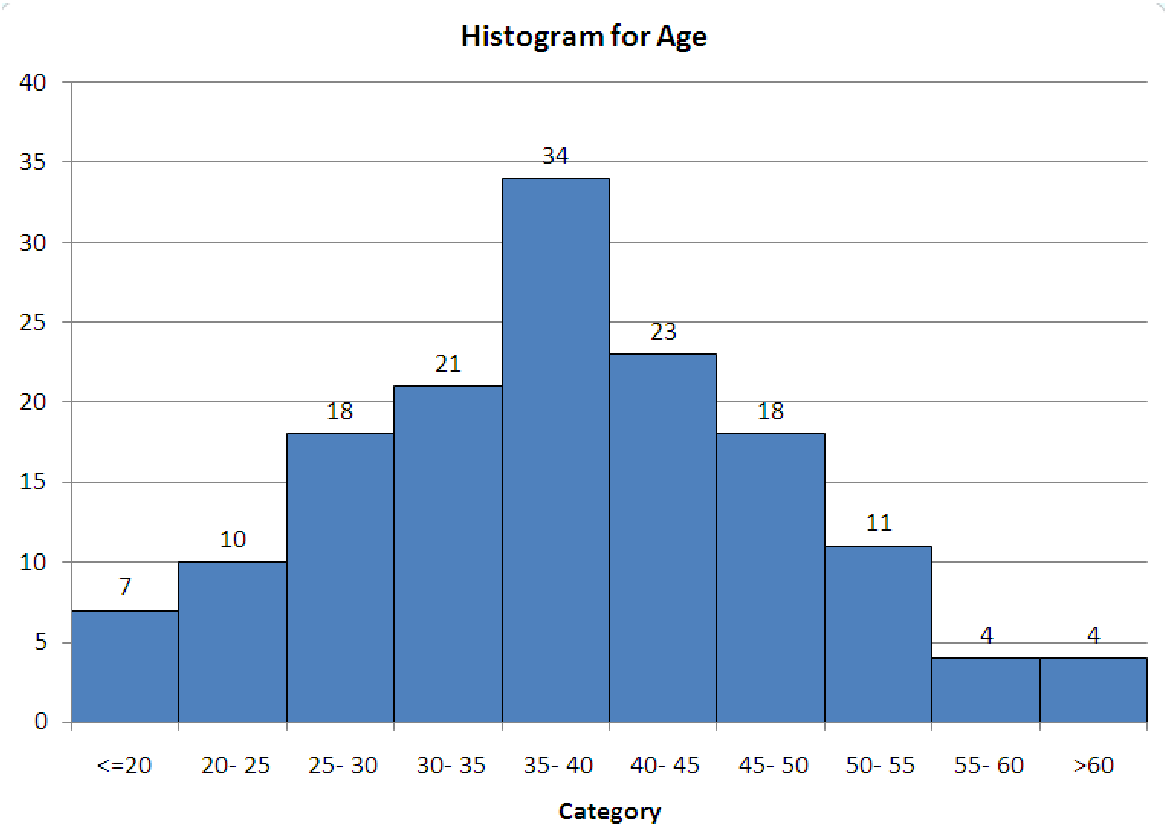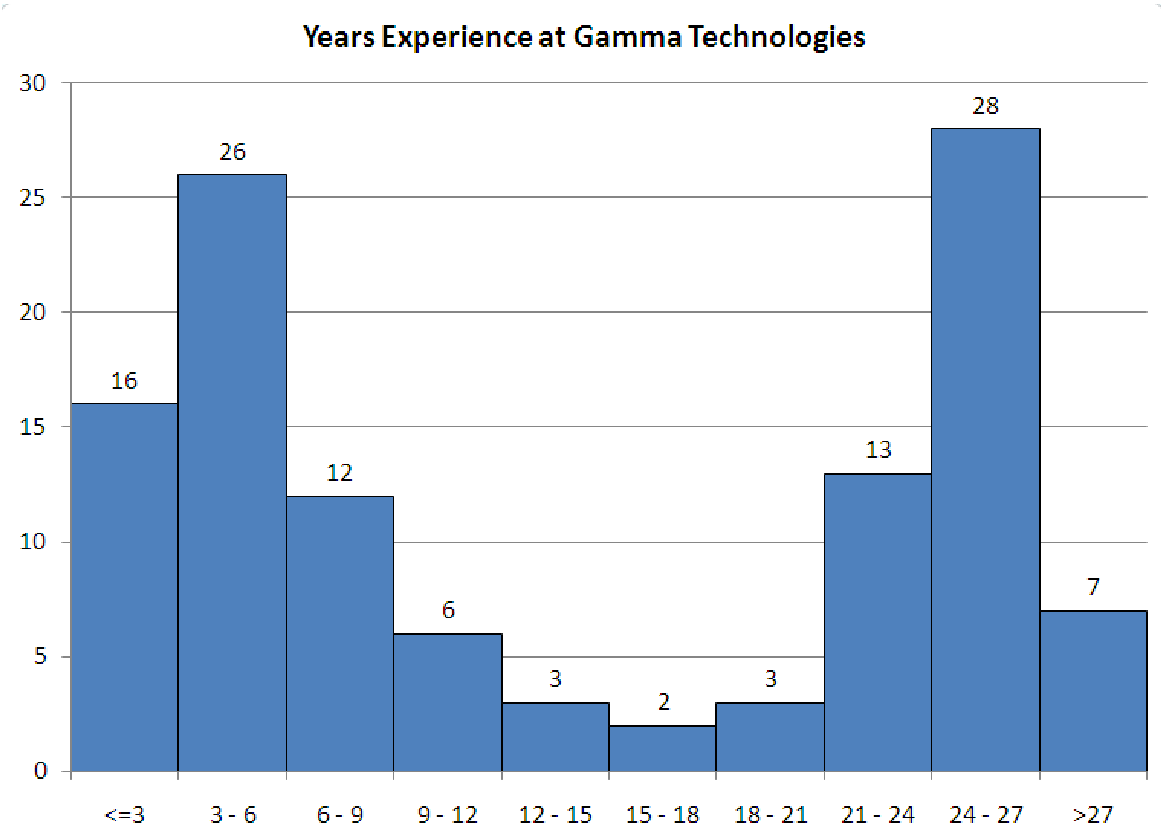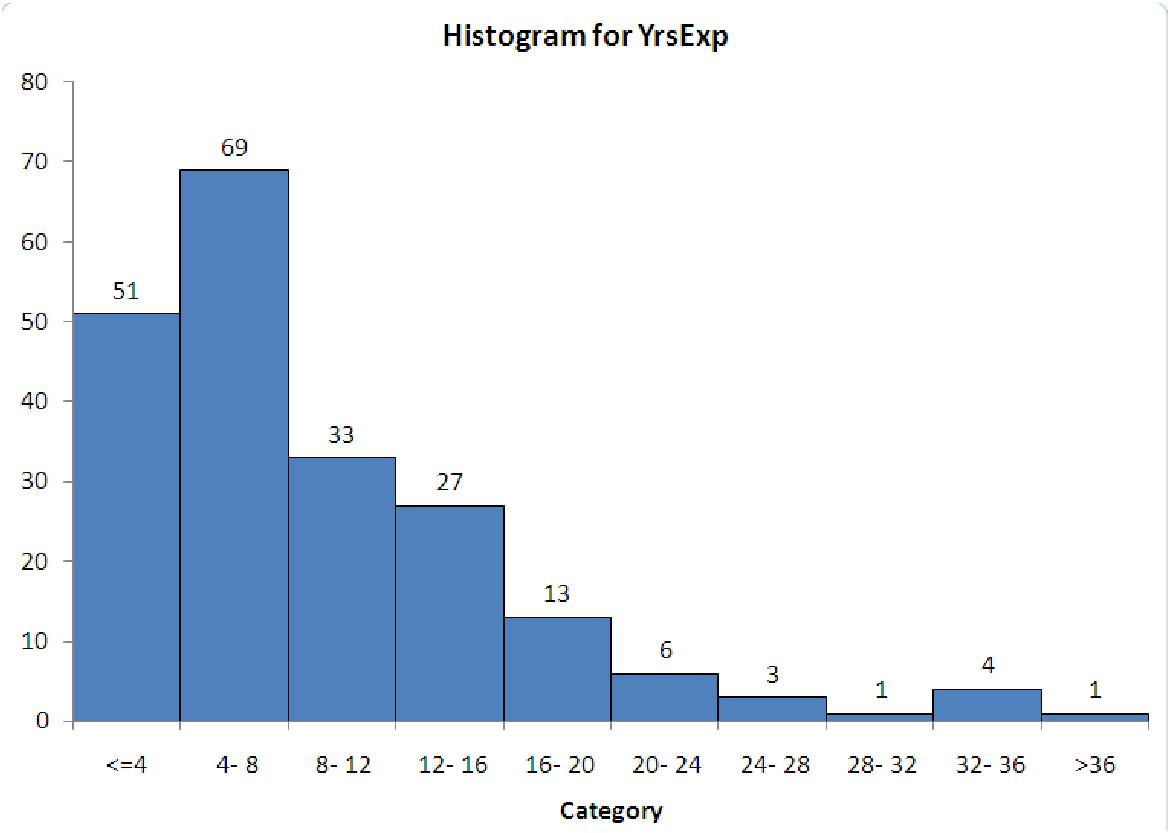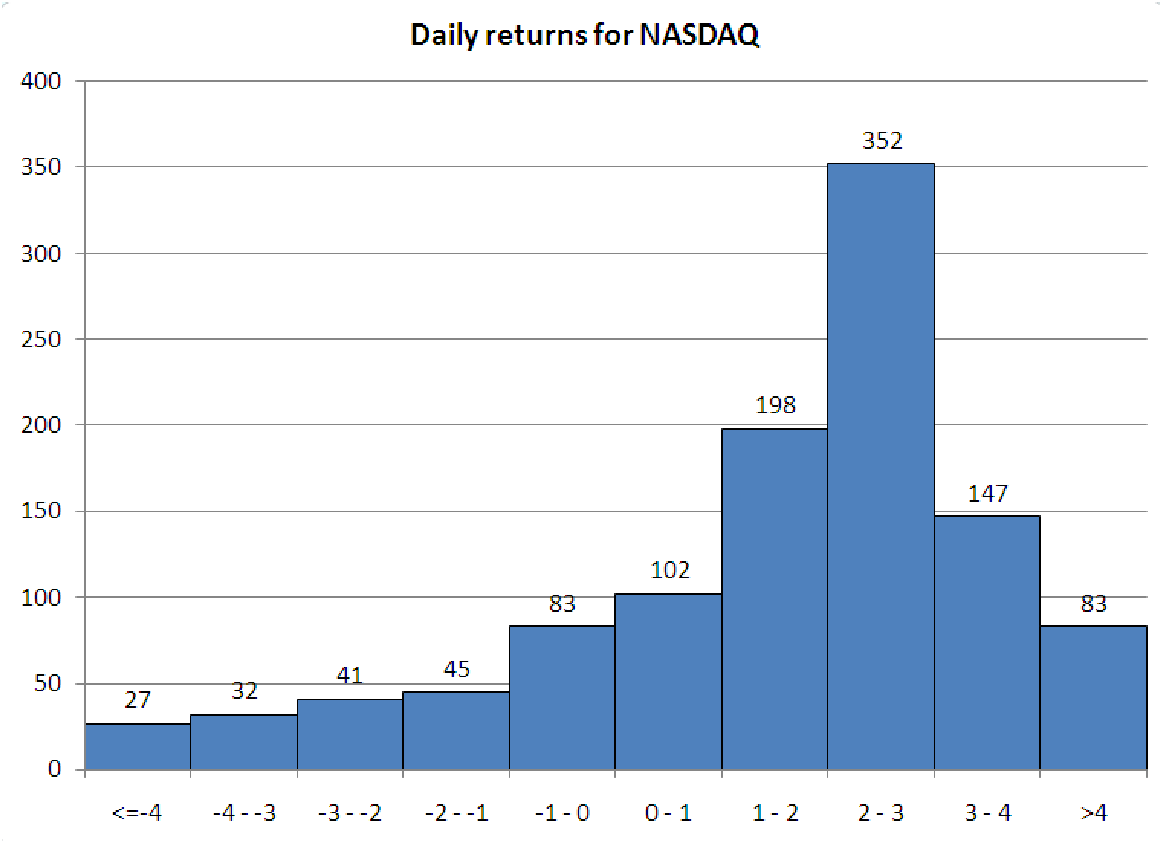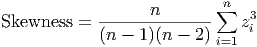
compares the data to the mean. If most of the data is less than the mean, then the skewness will be negative. If most of the data is greater than the mean, then the skewness is positive. The reason for this behavior is the exponent of three: data points far from the mean (and thus having a large deviation and a large z-score) will affect the total more than points close to the mean. In a positively skewed data set, the smallest values are much closer to the mean than the largest values, so the large positive deviations are made even larger by cubing them. The opposite happens for negatively skewed data.